
Mysql进阶篇-索引
概述
index , 是帮助Mysql 高效获取数据 的 数据结构(有序)
1 | 无索引的时候,查找数据就是最麻烦的全表扫面,从上到下扫一遍。 有索引的时候,很快,怎么这么快,看下面你就会知道。。。。 |
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列是要占空间的(可以忽略,磁盘很便宜) |
| 通过索引列进行数据排序,降低了数据排序的成本,降低CPU的消耗 | 索引提高了查询速度,但是降低了更新表的速度,Insert,update,delete时会低效率(增删改比例小,也可以忽略) |
**io成本就是数据从磁盘加载到内存时,需要花费的时间成本** ,不理解没关系,反正我现在也不知道,看完这篇md,你将会明白为什么能降低io成本,这个才是最重要的
数据结构
根据存储引擎的不同,索引的结构也不同
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎支持 |
| Hash索引 | 支持精确匹配索引查询,不支持****范围查询,不能排序 |
| R-Tree索引(空间索引) | 使用少,是MyISAM的一个类型,地理位置存储 |
| Full-text索引(全文索引) | 建立倒排索引,快速匹配文档 |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree(默认) | yes | yes | yes |
| Hash | no | no | yes |
| R-Tree | no | yes | no |
| Full-text | yes | yes | no |
索引结构
二叉树
会出现一堆问题所以要用下面的B+Tree
B-Tree(多路平衡查找树)
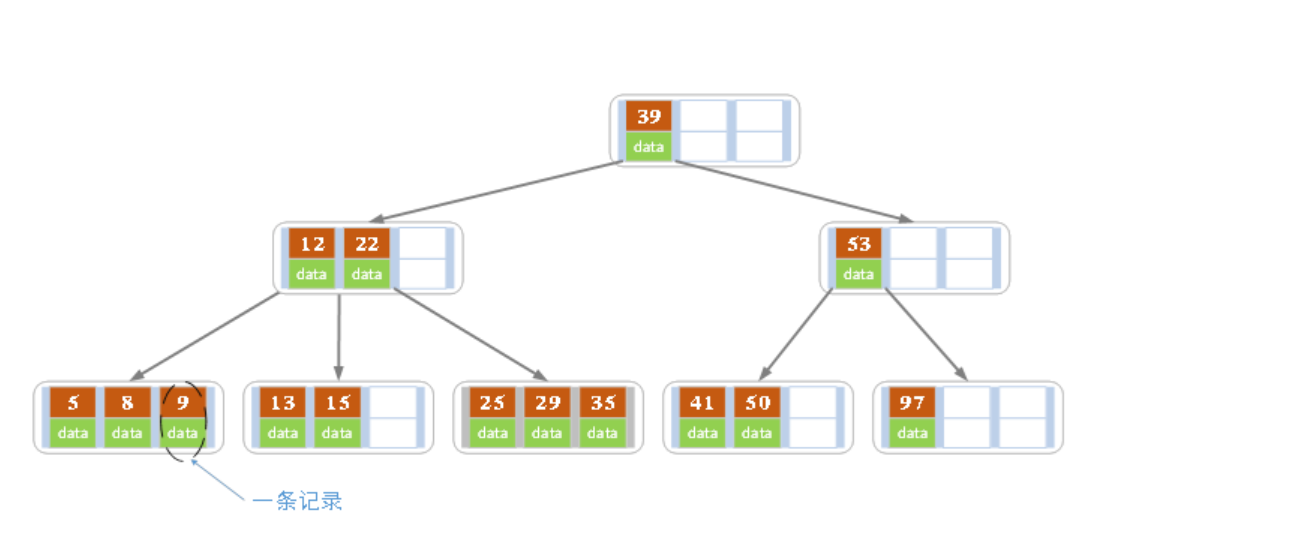
以一颗最大度数为5的B-Tree为例,每个节点最多存储四个Key,五个指针,有五个子节点
一棵最大度数为5的树 key 为10 20 30 40 这些数是在一个节点上,然后
10,1020,2030,3040,40~每个区间之间各有一个指针,指针指向其他节点,一共五个指针
因此,树的度数就是一个节点子节点的个数,也就是指针的个数
构造的过程中就是中间元素向上分裂
图中灰银色的区域就是一个指针,棕色和绿色的结合就是一个key,一个大框框就是一个节点
B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引。B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉树演化而来的。在讲B+树之前必须先了解二叉查找树、平衡二叉树(AVLTree)和平衡多路查找树(B-Tree),B+树即由这些树逐步优化而来。
B+Tree
由B-Tree进化而来
以一颗最大度数为4的B+Tree为例,每个节点最多存储3个Key,四个指针,有四个节点
B+Tree 所有的元素都会出现在叶子节点,叶子节点是用来存放数据的
非叶子节点只会起到一个索引的作用
叶子节点形成了一个单向链表,每个节点都会通过指针指向下一个节点
构造过程中,中间元素向上分裂的同时,元素还会留在叶子节点中
每个节点是存放在一个页中,一个页就是一个磁块
大部分与上述的特征差不多
叶子节点组成的是一个双向循环链表,每个相邻节点之间相互指向,同时包括头尾节点
一个叶子节点是存储在一个页中
实现看文档或者以后我的博客,估计会更新数据结构
Hash索引
Hash索引就是用Hash算法,将键值换算成新的Hash值,映射到相应的槽位中,然后存储在Hash表中
换句话说,就是媒婆将你夸得天花乱坠(键值换算)成A(Hash值),然后跟B(槽位)相亲,最后两个人走入洞房(Hash表中)
通过上述的大致原理的讲解,就可以明白Hash索引是支持精确值的查询,不支持范围查询,也没有办法通过索引完成排序操作,但是效率很高。
Mysql中支持Hash索引的是Memory引擎,InnoDB具有自适应Hash功能,通过B+Tree将Hash索引构建起来
再多说就蒙蔽了,快去学数据结构……….
思考
为什么InnoDB存储引擎选择使用B+Tree索引结构?
相对于二叉树,层级更少,搜索效率高
(重点)相对于B-Tree,一个节点通过一个页(磁盘块)来存放的,一页16K,如果非叶子节点不存放数据,相同一页情况下存储的指针就会变多,最大度数就会变大,自然高度就会变低,性能就会更好
并且不管查找哪个数据都需要到叶子节点去查找,搜索效率很稳定
B+Tree通过双向循环链表相连,便于排序和搜索
相对于Hash索引,可以支持范围搜索和排序操作
分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认创建,且唯一 | primary |
| 唯一索引 | 避免同一个表中某数据列的值重复 | 可以有多个 | unique |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 查找文本关键字 | 可以有多个 | fulltext |
根据索引的存储形式
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 | 将数据存储和索引放到了一块,叶子节点保存了行数据 | 必须有且唯一 |
| 二级索引 | 将数据与索引分开存储,叶子节点关联的是对应的主键 | 可以有多个 |
如果存在主键,主键索引就是聚集索引
如果不存在主键,将使用第一个唯一索引作为聚集索引
如果两个都没有,就会InnoDB自动生成一个rowid作为隐藏的聚集索引
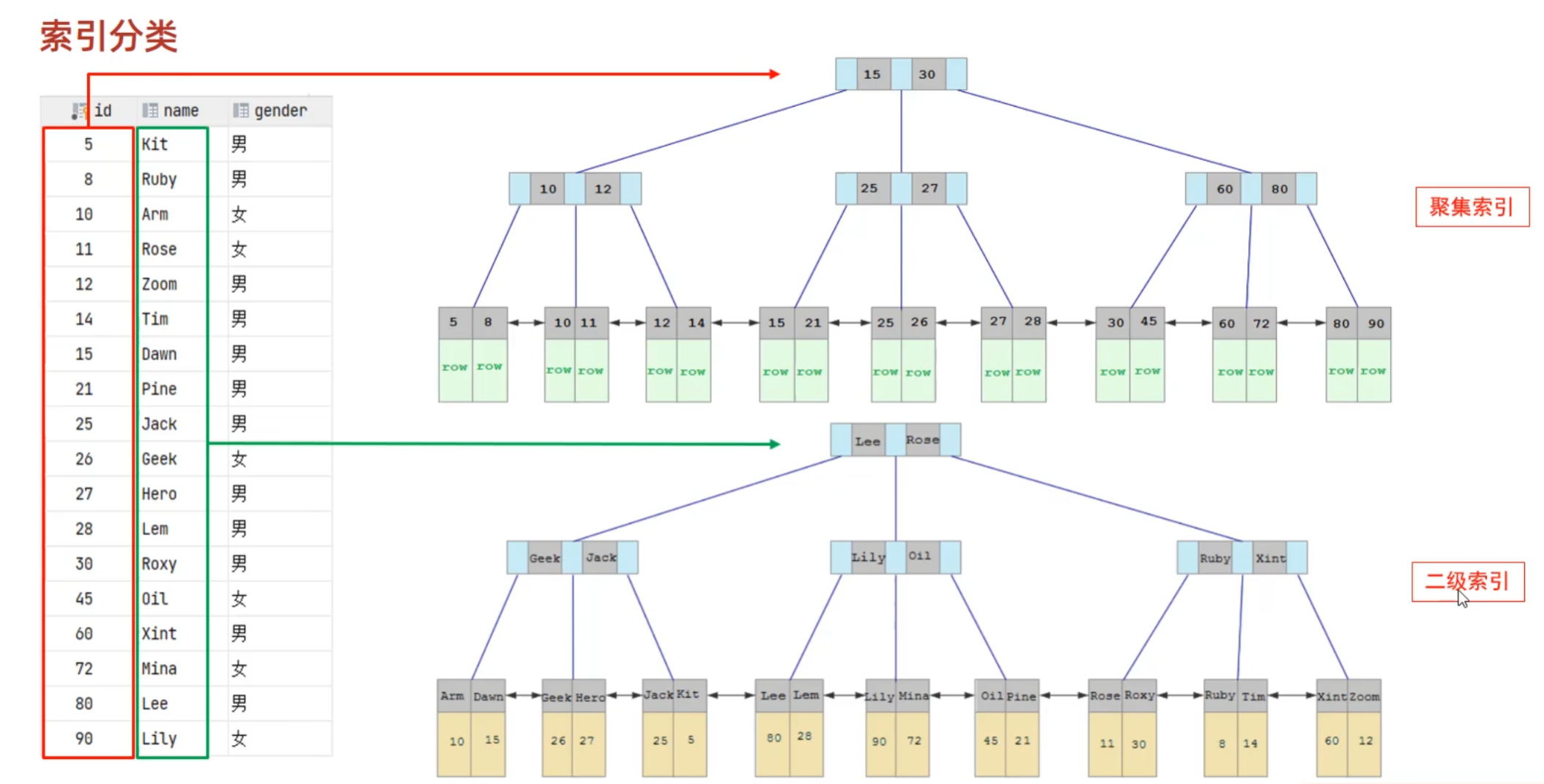
通过上图讲来讲解索引的作用
- 我们知道聚焦索引是叶子节点直接存储了行数据,例如存储了 (5|Kit|男)这一行数据,然后这些数据是通过id(主键来标识的),这也是为什么聚焦索引一定离不开主键(或唯一索引的原因)。
- 二级索引就是相对于行数据的简化了。它的每个叶子节点存储的是表中格子对应的主键 ,例如(Kit)(Ruby)(Arm),这些字段数据的排序则是通过字符串,数值的大小来排序的。
- 回表查询 ,假设我现在要查询 select * from People where name = ‘Kit’.
- 首先是二级索引,通过数值比较发现 ‘kit’ 的主键是’5’,
- 已知主键’5’,再去聚焦索引中寻找相应的行数据
- 得到数据为 5|Kit|男
- 通过图片观察两种索引的叶子节点,聚焦索引是主键下面携带行数据,二级索引是键值下面携带主键,因此可以回表查询
- 通过聚集索引和二级索引就可以明白SQL的优化操作的底层实现
思考
select * from user where id = 10
select * from user where name= ‘Arm’
备注:id是主键
当然是上面的高,原因就是我图片下面写的一堆文字—-> 第一个直接聚集索引,第二个回表查询,第一个高
假设: 一行数据大小为1K(1024字节),一页可以存放16行这样的数据,一页的大小 16 * 1024 = 16384 字节,
InnoDB指针占用6个字节的空间,主键即使为bigint也只占用8个字节的空间
设索引(键)的数量为 n ,键的总占用空间 : 键的数量 * 单个键的占用空间 = n * 8
根据B+tree树的特性,指针的数量比当前节点键的数量多1个,所以
指针的总占用空间 = ( 主键的数量 + 1 ) * 单个指针占用空间 = (n + 1) * 6
计算n 的值 : 每个页所占用的空间为 16384
列出方程 :
n * 8 + (n + 1) * 6 = 16384
14n = 16384 - 1
n = 16383 / 14
n ≈ 1170
现在已经 计算出键的数量为 1170 , 加1 就是指针的数量 1171
一个指针对应一页,一页可以有16行数据,1171 * 16 = 18736 行数据,得出当B+树高度为2的时候可以存储18736 行数据行
当高度为3的时候,你会发现每个叶子节点对应了1171个行数据,总共有1171个叶子节点
所以总数据行为 1171 * 1171 = 21939856 行数据
这里 一页就有十六行数据我有点不理解,难道叶子节点的头尾指针不算大小的么?
更多的了解数据库知识: