
mysql执行查询的流程
八股文的学习 现在开始,也是为了以后做准备吧
Mysql 执行一条 select 语句,到底是怎么实现的#
这是 小林Coding 的一幅图,我感觉清晰明了
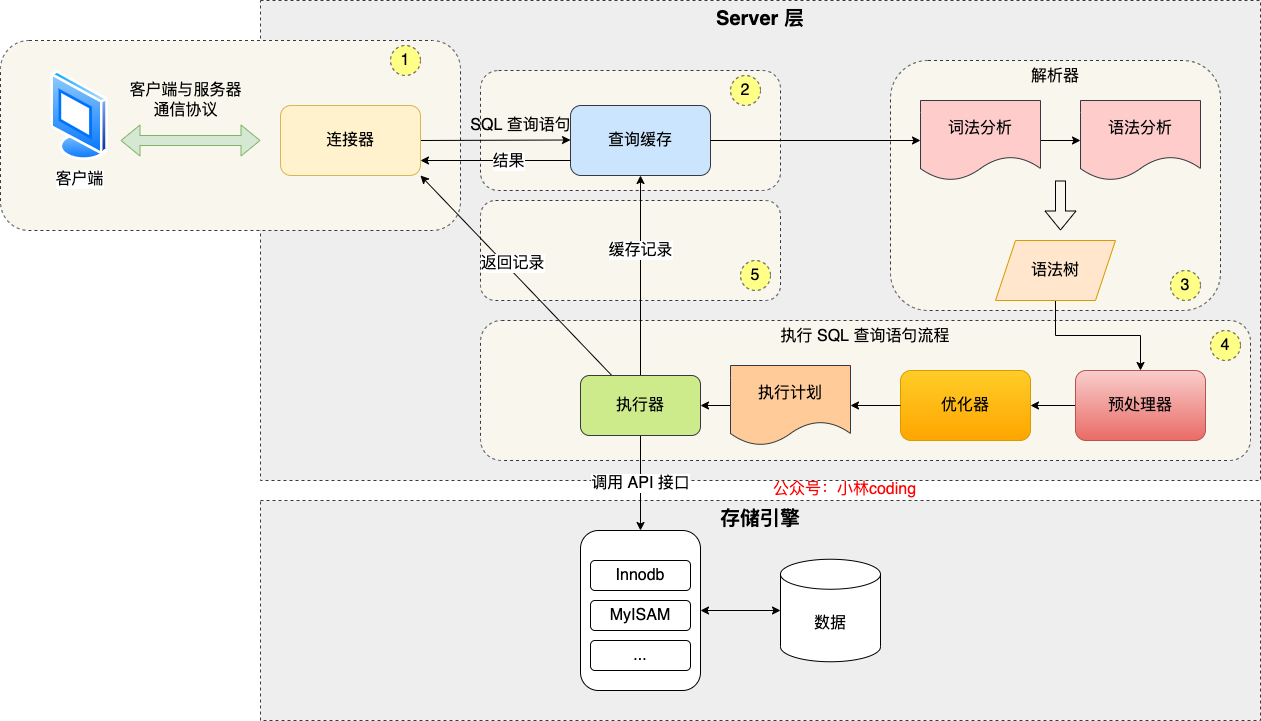
- Server 层(核心功能的实现)
- 连接器
- 查询缓存
- 解析器
- 预处理器
- 优化器
- 执行器
- 另外的一些功能
- 存储引擎层
- 存储引擎,一般来说是
InnoDB
- 存储引擎,一般来说是
大概的过程:
- 通过 连接器 连接数据库
- 当发生查询的时候,先查询缓存
- 解析 SQL 语句
- 执行 SQL
- 预处理阶段
- 优化阶段
- 执行阶段
连接器#
连接器大概干了这些事情
- 与客户端进行三次握手建立连接(mysql是遵循TCP协议的)
- 校验账号密码,获取权限
空闲连接的占用
mysql中定义的最长空闲时间 wait_timeout ,当超过的时候就会断开
最大连接数量
mysql中定义了最大连接数量 max_connections , 当超过的时候就会不再接收连接
连接形式
mysql的连接有 长连接 和 短连接 两种形式
短连接
连接TCP服务 -> 执行一条sql -> 断开TCP服务
长连接
连接TCP服务 -> 一直执行sql -> 断开TCP服务
如何解决长连接的内存占用问题
这个问题就相当于我们的电脑一直开着不关掉,同理
- 定期断开长连接
- 客户端重置连接
查询缓存#
这个特性在
mysql 8.0以后取消了因为当表总是改变的时候,查询缓存的命中率太低了
当然这里的缓存去除是 server 层的去除
而不是 存储引擎层 的缓存去除
预处理器#
解析 SQL 语句
他会将输入的 SQL 语句 分解层各个组成部分:
关键字,标识符,常量…………
词法检查
检查词语,语法是否正确
比如
from写成form,就会给你报错简单的语义分析
检查表名,列名 是否存在
优化器#
- 选择最佳执行计划
- 成本估算
总的来说就是通过成本估算来选择最佳执行计划
1 | select * from product where id = 1 |
比如上面这个案例,就是用索引进行查询的
执行器#
这一块内容我不是很理解
执行器是和存储引擎进行交互的,也就是拿着优化器的方案干活
- 主键索引查询
- 全表扫描
- 索引下推
主键索引查询#
主键索引保证了每个键值的唯一性,因此这是数据库中效率最高的查询类型之一
虽然小林讲的我有点蒙蔽,但是喂给GPT后就清楚很多了
- 第一次查询:
- 执行器调用
read_first_record函数指针指向的函数。这个函数由InnoDB存储引擎实现,用于定位第一条符合条件的记录。 - InnoDB使用B+树结构的主键索引来查找
id = 1的记录。
- 执行器调用
- 记录定位:
- 如果
id = 1的记录存在,InnoDB将其定位并返回给执行器。 - 如果记录不存在,InnoDB上报错误给执行器,比如 “Record not found”,查询结束。
- 如果
- 记录验证:
- 执行器接收到记录后,会检查记录是否完全符合查询条件。
- 如果记录符合条件,执行器将其发送给客户端。
- 如果记录不符合条件(虽然这种情况在使用主键查询时不太可能发生),执行器将跳过这条记录。
- 循环查询:
- 如果查询需要返回多条记录(比如使用了
LIMIT子句),执行器将进入一个while循环。 - 在循环中,执行器调用
read_record函数指针指向的函数来获取下一条记录。
- 如果查询需要返回多条记录(比如使用了
全表扫描#
当查询条件不能有效利用索引或者表没有合适的索引时一般会使用这种方法,但是这种方法非常的耗时耗资源
- 查询优化:查询优化器分析查询,确定没有可用的索引或者索引不适用于当前查询,决定执行全表扫描。
- 打开表:数据库引擎打开要扫描的表,准备进行数据检索。
- 读取数据:数据库引擎开始从表的第一个数据块或行开始读取数据。由于没有使用索引,必须检查表中的每一行数据。
- 应用条件:对于每一行数据,数据库引擎检查是否满足查询条件。如果满足,这行数据将作为查询结果的一部分。
- 处理数据:如果查询包含排序(
ORDER BY)、分组(GROUP BY)或聚合函数(如SUM、COUNT等),数据库引擎需要对满足条件的数据进行相应的处理。 - 返回结果:满足查询条件的数据行被发送回客户端。
索引下推#
小林讲的很详细,但是我觉得不够简洁,索引下推概括来说就是:
将部分查询条件的检查工作“下推”到存储引擎层实现,而不是在数据库服务层(Server Layer)进行。
然后通过小林的例子就会理解很清楚
1 | select * from user where age > 10 and reward =1000 |
当 age , reward 为联合字段时
普通查询
先在存储引擎层查询
age > 10,然后回表将记录返回给server层,让server层查询这条数据是否reward = 1000我们会发现在这次查询中,几乎每次查询都需要进行回表,如果
age>10的情况非常多而reward=1000非常少,就会导致我们不停地回表,从而导致我们的资源浪费索引下推
直接在存储引擎层查询
age>10,查询到后不回表,而是继续在存储引擎层 验证这条数据是否reward = 1000,如果成功就把这条数据返回给server层,这样我们可以发现我们不需频繁地进行回表操作,减少资源浪费所以,索引下推的操作就是把部分的查询操作在存储引擎层实现,减少回表的资源浪费