
k8s核心概念
什么是k8s#
k8s 是面向资源的,一切皆资源,我们可以通过json,yaml(一般用yaml)等方式来描述资源(Pod,Service,Node)
资源和对象映射到JAVA中,资源相当于Java中的类,而对象就是类形成的实例
pod 是最小的调度单位,k8s 最终的资源呈现都是以pod为形态展现的。
pod 相当于底层的一个单位。
kubernetes , 是容器编排引擎,是为了让容器部署更加方便,可以管理云平台中多主机上的容器化应用,正常之前的DevOps(Docker Compose)是可以实现在单主机上的应用
传统部署 vs 虚拟化部署vs 容器化部署#
传统部署
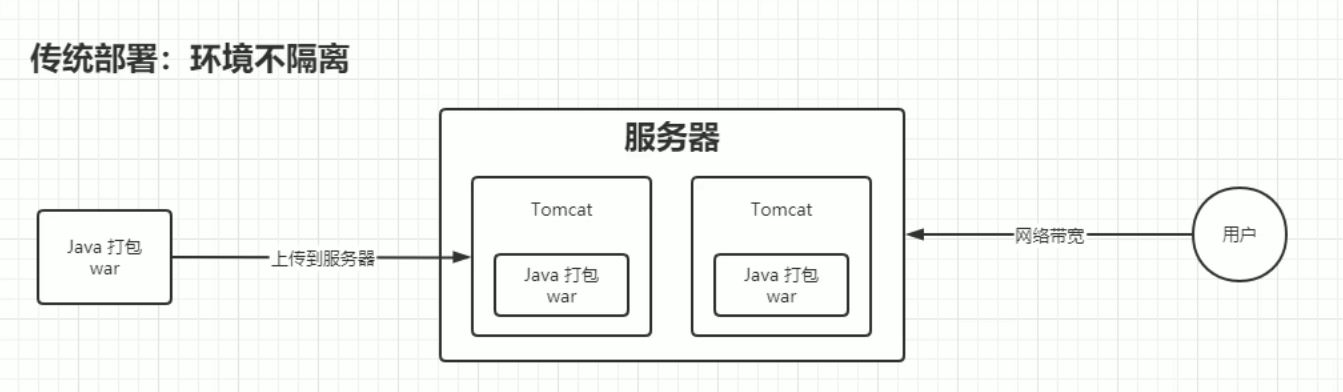
- 人工频繁:人们需要很繁琐地去部署,维护
- 并发问题:当应用A和应用B同时修改某个文件的时候,就会出现并发问题
- 网络带宽的资源缺少问题:应用A和应用B同时占用同一个带宽,网络拥挤
- CPU,磁盘的资源争抢问题:同上
虚拟化部署
将服务器虚拟化,在一个物理服务器上划分为许许多多的虚拟机
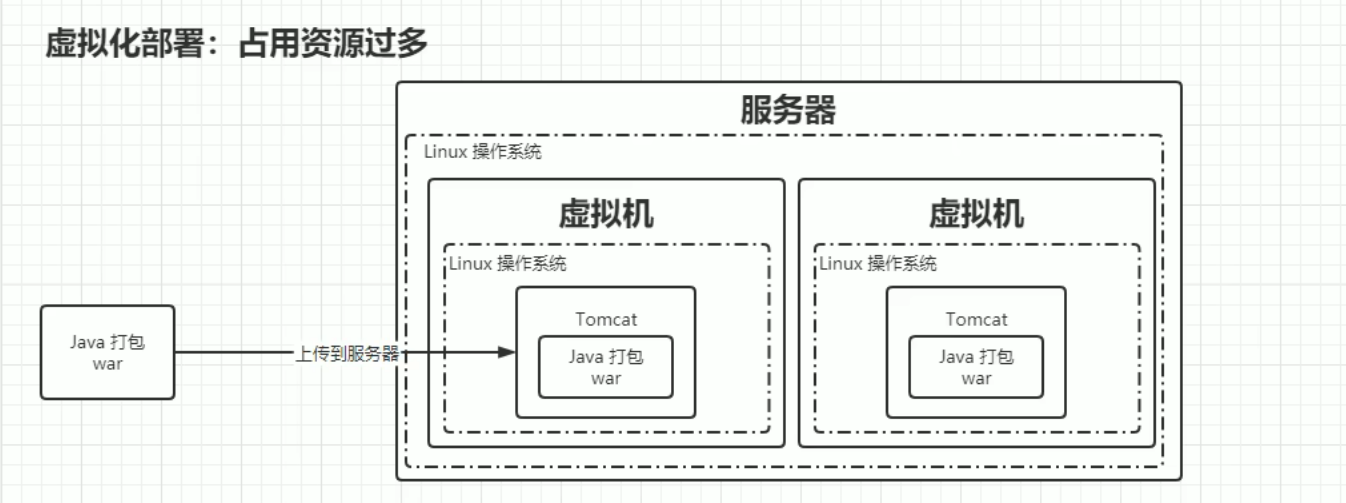
但是会出现不必要资源占用的情况,即启动一个虚拟机需要的资源太多了,但是如果一个虚拟机上只安装了一两个应用就会方向整个操作系统有很多资源是冗余的。
容器化部署
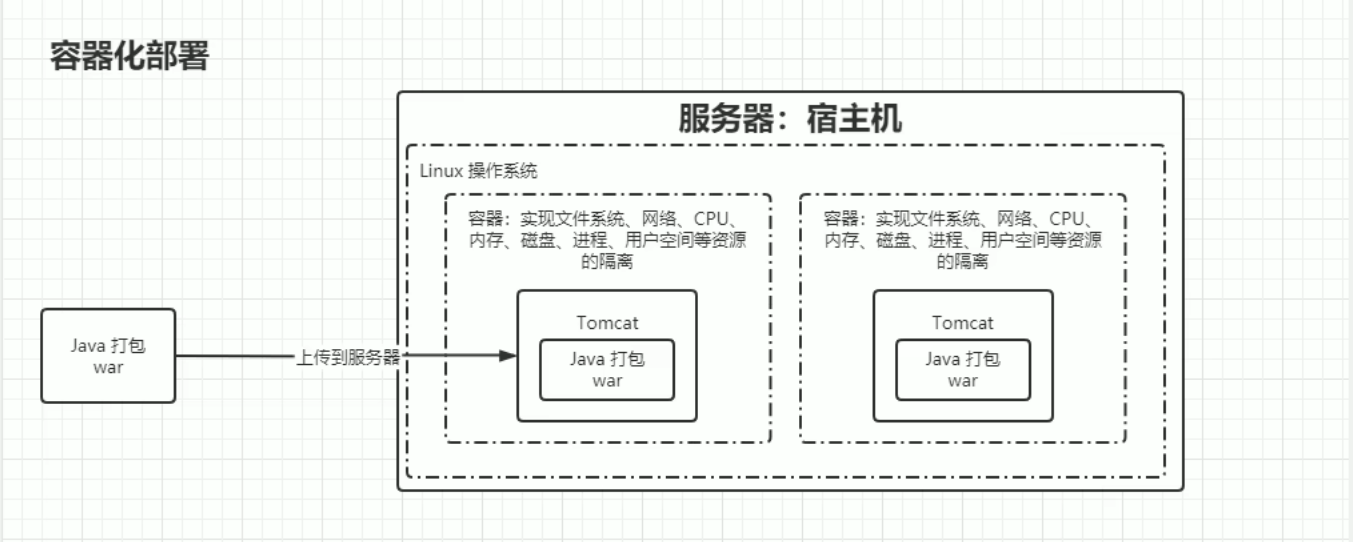
问题: 容器只是一个壳子,生命周期很短,用完后就会删除
容器删除后,我的网络,cpu都不是那么的稳定了,从而导致我的config中的某些配置可能并不是那么的正确了…………..
- 自我修复:如果原来的容器出现错误,那么k8s会把你原来的容器干掉,重新开一个容器出来
- 弹性伸缩:可以自动扩展或者删除我需要的容器的数量
- 自动完成部署等等 …………
核心概念#
应用的状态#
无状态应用
例如Ngnix,不会对本地环境产生任何依赖,例如不会存储数据到本地磁盘
有状态应用
例如Redis,会对本地环境产生任何依赖,会有数据恢复,数据初始化等操作
对象的规约和状态#
规约(spec)
可以理解为规格,描述的是对象的期望状态,通过声明式来描述,而不是必须
状态(status)
这个表示对象的实际状态,该属性由k8s的控制器进行管理,尽可能符合
spec期望状态
资源分类(了解一下)#
集群
一般来说是整个k8s集群,包括了很多节点
集群级别的资源就是作用于集群之上,集群下的所有资源都可以共享使用哦
- Namespace 命名空间,有时候命名空间也是一种资源
- Node,这是一台服务器
- ClusterRole + ClusterRoleBinding 用于集群资源上的鉴权
命名空间(important)
一个集群可以划分多个命名空间,也就是逻辑意义上的集群
1.
元空间
更多是资源的元数据的描述,也就是每一个资源都可以使用元空间的数据
HPA(Horizontal Pod Autoscaler)
这个是Pod自动根据cpu或者自定义的一个指标去进行一个扩容缩容
PodTemplate
Pod模板,根据这个模板来创建Pod
LimitRange
是用来做一个限制,限制最多能够用多少资源
[!NOTE]
下面的所有内容都是属于命名空间级资源的核心概念
Pod#
为什么要使用Pod?
Pod(容器组)是 Kubernetes中最小的可部署单元。一个Pod(容器组)包含了一个应用程序容器(某些情况下是多个容器)、存储资源、一个唯一的网络IP 地址、以及一些确定容器该如何运行的选项。Pod 容器组代表了Kubernetes 中一个独立的应用程序运行实例,该实例可能由单个容器或者几个紧耦合在一起的容器组成(正常来说应用程序和数据库并不是紧耦合的)。
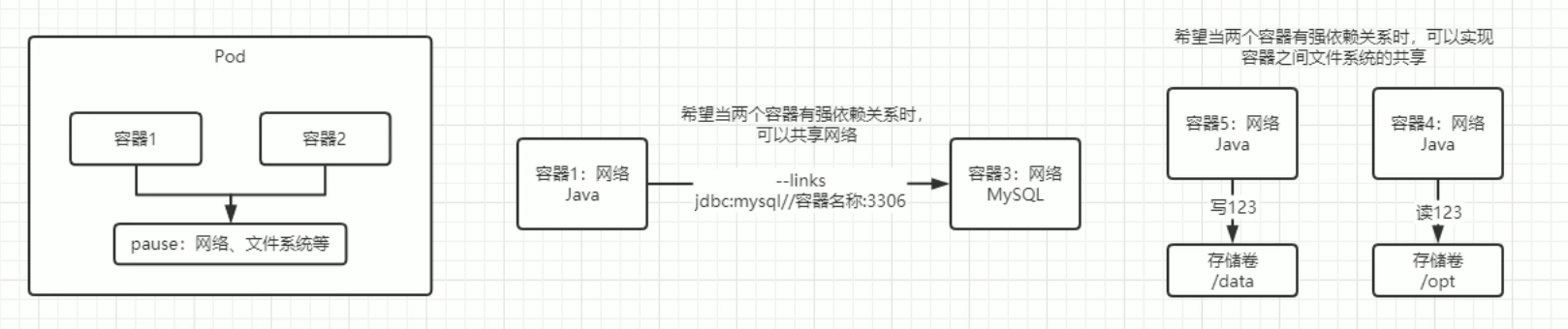
当我们使用容器的时候会发现不同容器中的文件系统,网络是不同的,因此如果要访问对方的文件系统或者网络就会出现很大的问题,也就是共通性的不足,因此需要使用Pod,可以理解为容器组,这个组中的容器共享网络,进程,文件系统…..
当然这些共享功能实现是通过Pause容器来实现的,所以一般来说Pod这个框底层有个pause的小框
使用途径:
- 一个 Pod 中只运行一个容器。
one-container-per-pod是Kubernetes 中最常见的使用方式。此时,您可以认为 Pod容器组是该容器的 wrapper,Kubernetes 通过 Pod 管理容器,而不是直接管理容器。 - 一个 Pod 中运行多个需要互相协作的容器。您可以将多个紧密耦合、共享资源且始终在一起运行的容器编排在同一个Pod 中。
副本(replica):
一个 Pod 可以被复制成多份,每一份可被称之为一个“副本”
这些“副本“除了一些基本描述性的信息(Pod的名字、uid等)不一样以外,其它信息都是一样的,如 Pod内部的容器、容器数量、容器里面运行的应用等的这些信息都是一样的,这些副本提供同样的功能。
Pod的名字和uid会自动做调整,变成唯一的
副本数一般来说会在控制器里面,“控制器”通常包含一个名为“replicas”的属性。“replicas属性则指走了特定 Pod 的副本的数量,当当前集群中该 Pod 的数量与该属性指定的值不一致时,k8s会采取一些策略去使得当前状态满足配置的要求。
Pod管理的是容器,不一定是Docker的容器,只要是容器化的应用程序就可以呃
控制器#
他就是一个Pod,但是在Pod上面做了一些封装
他是描述了对Pod的一系列相关的参数,他就可以控制Pod的自动扩增和缩减
控制器 种类:
| 无状态服务 | 有状态服务 | 守护进程 | 任务/定时任务 |
|---|---|---|---|
| Deployment - 在扩容的基础上,提供了更加丰富的部署相关的功能(自动创建Pod/滚动升级回滚/扩容缩容/暂停与恢复Deployment) | StatefulSet(Headless,volumeClaimTemplate) | DaemonSet | Job/CronJob |
Deployment
滚动升级/回滚
如果对Pod版本进行升级,Deployment会把原来的版本中第一个
Pod1复制出为Pod1’然后对
Pod1'升级,如果升级后的Pod1'能够正常运行,则继续对Pod2进行上述的操作到所有都升级完后,旧版本的内容会保留,用来回滚
这样子升级可以在应用使用的情况下升级,同时还可以回到老版本,非常好用
平滑的扩容/缩容
依赖Replica Set 进行扩容/缩容
暂停和恢复
就是在升级过程中,想要对模板信息进行修改,可以对升级的版本进行暂停,修改完后恢复
Pod发现自己的状态和期望状态不统一后就会进行修改
StatefulSet
但我把某个包含数据库容器的Pod删除再建立后,有如下问题:
内部的网络是不一样的
内部的数据也是不一样的
节点之间的顺序关系
解决工具:
Headless Service
他会帮我们把每个Pod取一个名字,每个名字可以映射成DNS,进行访问
Statefulset 中每个Pod的 DNS 格式为
statefulSetName-{0..N-1}.serviceName.namespace.svc.cluster.localvolumeClaimTemplate
用于创建持久化卷的模板
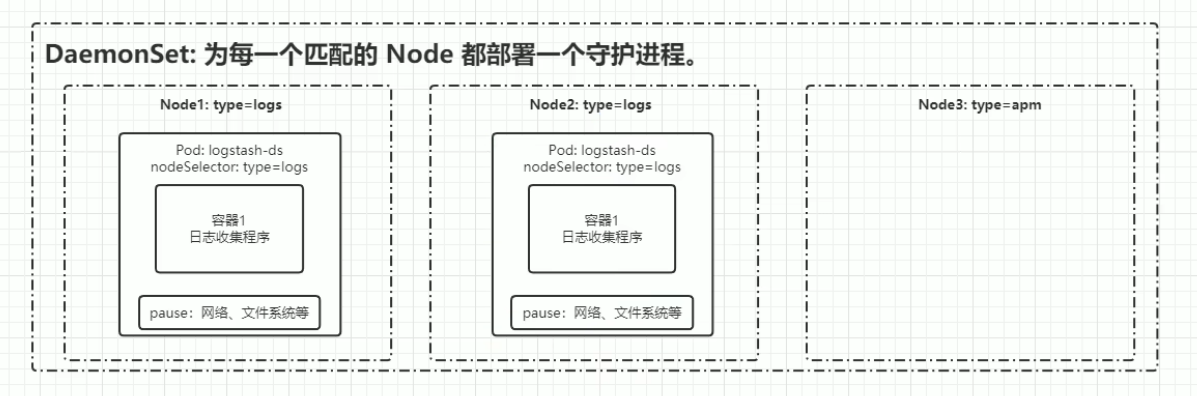
DaemonSet
Daemonset保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志收集、系统监控或者其他系统管理应用。
我们写一个模板,他就会自动保护进程
Job/CronJob
一次性任务,运行完成后Pod销毁,不再重新启动新容器
周期性任务,在某个时间点做什么事情
服务发现#
Service
k8s集群内的网络通信,跨节点Pod与Pod之间的通信通过暴露端口实现
Ingress
外网访问k8s集群内的功能实现
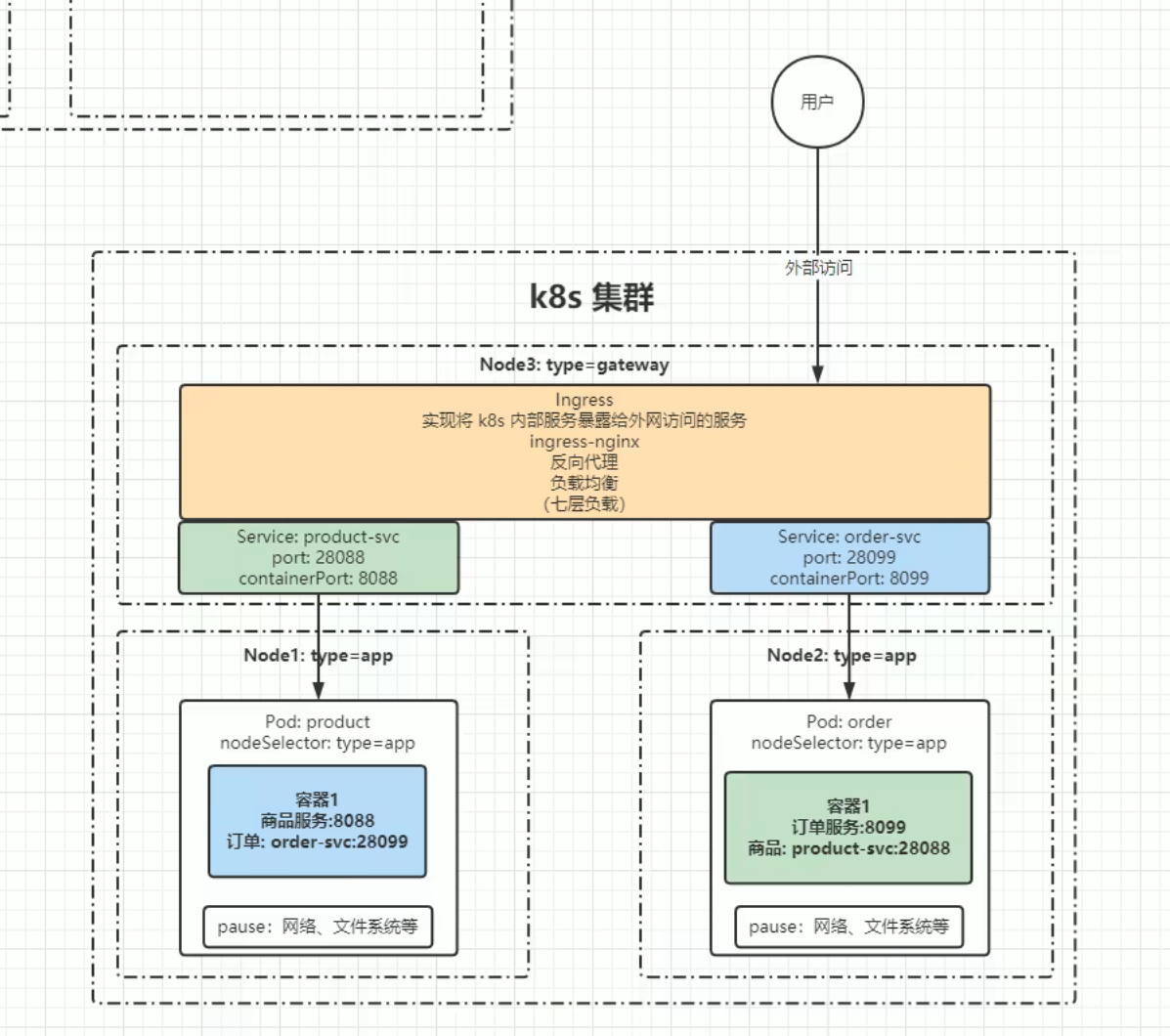
感觉下面两张图看起来够清楚了,不需要什么解释了
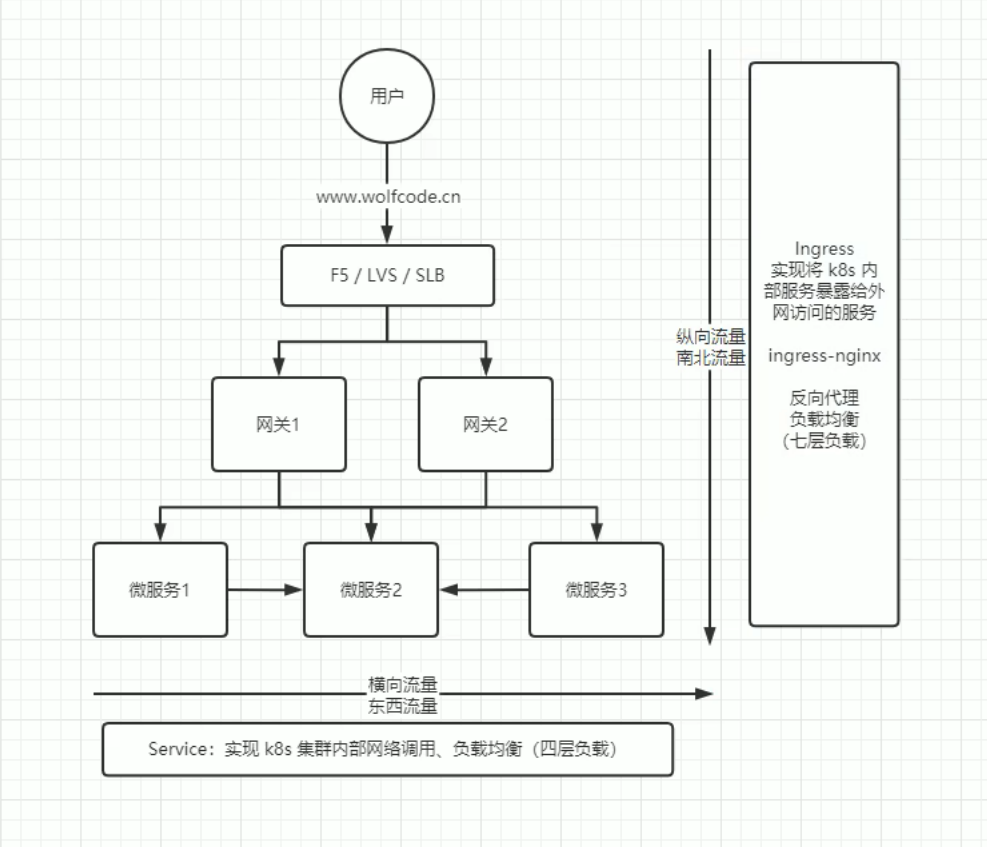
F5/LVS/SLB 这是负载均衡的东西
下面这张图的 Port-ContainerPort 的映射这个参考容器知识
存储#
Volume
数据卷,共享Pod中容器使用的数据,用来放持久化的数据
CSI
暴露接口,使得任意存储系统暴露给容器化应用程序。
特殊类型配置#
ConfigMap
key-value类型的数据放到容器中运行但我要修改某些容器的配置,我只要修改ConfigMap中的配置就可以灵活修改容器中的配置,而不是配置写死在容器中。
Secret
与
ConfigMap类似,会多出一个加密的操作DownwardAPI
将Pod的信息共享到容器内
- 环境变量:用于单个变量,可以将 pod 信息和容器信息直接注入容骼内部
- volume 挂载:将 pod 信息生成为文件,直接挂载到容器内部中去
文件与数据库#
想要让应用程序更新需要数据库的更新
数据库的更新
1
kubectl apply -f xxx.yaml
1
kubectl edit deploy xxx.yaml
文件的更新
1
vim xxx.yaml
但只是修改了文件的更新时,应用程序并不会更新
对 UI 来说,UI的更新是在数据库层面的直接更新,但是原本的文件没有更新
因此在 Lens 上修改 UI 的 configMap 时 会在后续的 CI/CD 时被覆盖
最后重点关注的两方面#
- spec
- kubectl