依赖倒转原则 Dependence Inversion Principle, DlP
高层模块不应该依赖低层模块,二者都应该依赖其抽象
抽象不应该依赖细节;细节应该依赖抽象 == 依赖抽象而不是依赖于具体的实现
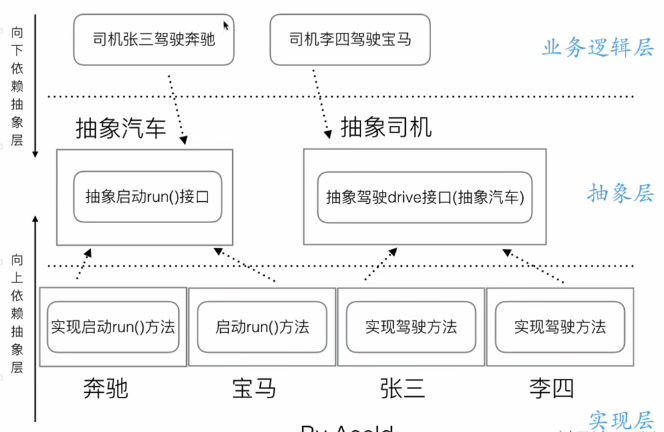
可以理解为 实现层,也就是轮子
可以理解为 业务逻辑层,也就是车子,车子需要轮子建造起来
也就是会在业务逻辑层和实现层之间抽离出一个抽象层、
业务逻辑层向下依赖于抽象层,实现层线上依赖于抽象层,也就实现了依赖倒转的模样
bilibili 刘丹冰 + 100个Go语言错误
现在我们有个业务场景:
实际操作: 现在有司机: 张三李四;汽车: 宝马,奔驰,
然后 - 张三开奔驰 - 李四开宝马
原代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package mainimport "fmt" type Benz struct {}func (b *Benz) fmt.Println("Benz is running" ) } type Bwm struct {}func (b *Bwm) fmt.Println("Bwm is running" ) } type Zhang3 struct {}func (z *Zhang3) fmt.Println("Zhang3 is driving Benz" ) b.Run() } type Li4 struct {}func (l *Li4) fmt.Println("Li4 is driving Bwm" ) b.Run() } func main () zhang3 := &Zhang3{} li4 := &Li4{} benz := &Benz{} bwm := &Bwm{} zhang3.Drive(benz) li4.Drive(bwm) } Zhang3 is driving Benz Benz is running Li4 is driving Bwm Bwm is running
很好,这个代码很像是我会写出来的那种丑陋,那么下面思考一个问题,如果现在张三要开宝马,李四要开奔驰;我们这个丑陋代码应该怎么写
在不能修改源代码的前提下,我应该会再创建一坨方法来对应相应的关系,由此可以看出
车 - 人 关系错综复杂,耦合度非常高,因此我们要引入依赖倒转原则,抽象出一个抽象层
现在我们知道了,车有一个共同的行为Run() ,而人也有一个共同的行为Drive()
下面是用接口来减小耦合度,提高代码的复用性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 type Car interface { Run() } type Bmw struct {}func (b Bmw) fmt.Println("BMW is running" ) } type Benz struct {}func (b Benz) fmt.Println("Benz is running" ) } type Person interface { Drive(Car) } type Zhang3 struct {}func (z Zhang3) fmt.Println("Zhang3 is driving" ) c.Run() } type Li4 struct {}func (l Li4) fmt.Println("Li4 is driving" ) c.Run() } func main () var bmw Car bmw = Bmw{} var benz Car benz = Benz{} var p1 Person p1 = Zhang3{} fmt.Println("Zhang3 is driving BMW" ) p1.Drive(bmw) fmt.Println("Zhang3 is driving Benz" ) p1.Drive(benz) var p2 Person p2 = Li4{} fmt.Println("Li4 is driving BMW" ) p2.Drive(bmw) fmt.Println("Li4 is driving Benz" ) p2.Drive(benz) } Zhang3 is driving BMW Zhang3 is driving BMW is running Zhang3 is driving Benz Zhang3 is driving Benz is running Li4 is driving BMW Li4 is driving BMW is running Li4 is driving Benz Li4 is driving Benz is running
在上面的代码设计里面我们可以发现一个事情:
设计车辆的时候不需要思考某个人来开这辆车;某个人驾驶汽车的时候只需要考虑自己的驾驶技术,而不需要考虑驾驶的是什么车,当使用c.Run()的时候,不需要考虑这个Run()的具体实现形式
如果需要其他人来驾驶Bwm/zhang3需要驾驶其他车的时候,我们可以很轻易的地写出一个模块来对应他,非常nice
结构体里放接口 结合上面的案例思考一下下面这样的设计模式有什么作用:
1 2 3 type Service struct { logger Logger }
如果是之前的我肯定会这样设计:
1 2 3 type Service struct { logger Logger }
那么上面的设计有什么好处呢?
假设我们有一个应用程序需要记录日志。为了实现日志记录,我们可以定义一个Logger接口,并提供不同的实现,如控制台日志记录和文件日志记录。业务逻辑模块将依赖于Logger接口,而不是具体的日志实现,这样可以方便地切换日志记录方式,而无需修改业务逻辑代码。
下面是o1-mini生成的代码,我觉得很有道理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 package mainimport ( "fmt" "os" ) type Logger interface { Log(message string ) } type ConsoleLogger struct {}func (c *ConsoleLogger) string ) { fmt.Println("Console Logger:" , message) } type FileLogger struct { file *os.File } func NewFileLogger (filename string ) error ) { f, err := os.OpenFile(filename, os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644 ) if err != nil { return nil , err } return &FileLogger{file: f}, nil } func (f *FileLogger) string ) { f.file.WriteString("File Logger: " + message + "\n" ) } type Service struct { logger Logger } func NewService (logger Logger) return &Service{logger: logger} } func (s *Service) s.logger.Log("Service is doing something." ) } func main () consoleLogger := &ConsoleLogger{} service1 := NewService(consoleLogger) service1.DoSomething() fileLogger, err := NewFileLogger("app.log" ) if err != nil { fmt.Println("Error initializing FileLogger:" , err) return } defer fileLogger.file.Close() service2 := NewService(fileLogger) service2.DoSomething() }
简单来说就有这些优点:
这一点也就是刚刚的人与汽车的实例体现
Service只需要知道Logger接口的存在和它的方法签名,而不关心具体的实现细节。这意味着你可以在不修改Service代码的情况下,替换或添加新的日志记录实现。
如果未来需要添加一个新的日志记录方式,例如将日志发送到远程服务器,只需实现一个新的Logger接口类型,而无需改变Service的代码。
这个优点是上面一个优点的附带产品
在编写单元测试时,可以为Logger接口创建一个模拟(mock)实现,避免依赖于实际的日志记录机制。这使得测试更加独立和高效。
如果在业务代码中我们的Logger依赖于外部环境难以实现且我们测试内容不在这个方面,这个时候我们可以自定义一个testLogger,来实现Log接口,从而实现测试,非常好用😍😍
1 2 3 4 5 6 7 8 9 10 11 12 type testLogger struct {}func (testLogger) string ){ fmt.Println(message) } func testService (t *testing.T) tL := testLogger{} srv := NewService(tl) srv.Dosomething() }
由于Service依赖于接口,任何实现了Logger接口的类型都可以被Service使用。相信你能体会到
请让消费者定义接口 接口应由使用它们的代码(消费者)定义,而不是由实现它们的代码(生产者)定义 。
消费者 :在软件设计中,消费者是指使用某个接口或服务的组件或模块。消费者依赖于接口来执行其功能,但并不关心接口的具体实现细节。
生产者 :生产者是指提供服务或实现接口的组件或模块。生产者负责实现接口定义的方法。
结合上下文来说:
比如说 Zap 的logger ,这个Zap.SuggerLog 是生产者,他生产出了一个Log给消费者使用,而消费者就是具体业务代码的实现者,他们就会使用生产者产出的这个Log 进行日志记录
那么为什么要在消费者处定义?
假设我们要发邮件给某个人,用我们的需求(消费者)定义一个接口:
1 2 3 type Notifier interface { Send(message string ) error }
那么如果是以(生产者)的视角来定义一个接口:
我们总是会浮现连篇: 我们好像可以用id发邮件,用姓名发邮件,用gpt发邮件~~~~
1 2 3 4 5 6 type Notifier interface { SendByName(message string )error SendById(message string )error SendByGpt(message string )error }
可问题是我们作为消费者根本不需要实现这么多接口,很多接口的实现对于我们业务环境并没有什么帮助,反而导致了代码冗余
从这就可以得出一个接口的重要原则:
不要用 接口进行设计,要发现接口
因为接口有很大的局限性,他必须要满足接口才能进行使用,通常接口都还会当作限制某个struct行为的工具
当然,万事不是绝对的
从本质出发看消费者和生产者我们会发现消费者是动态的而生产者是动态的,那么如果消费者的某个需求也是一成不变的时候,就是可以从生产者方定义接口的时候:
1 2 3 4 5 6 type Interface interface { Len() int Less(i, j int ) bool Swap(i, j int ) }
当然这需要我们从本质上去发现接口,显然这是非常困难的
最后:
不要返回接口 这里引入一个设计原则:
做什么要保守,接收什么要自由 ”
做什么要保守 :在函数或方法的返回值上,倾向于返回具体类型(结构体),而不是接口。接收什么要自由 :在函数或方法的参数上,倾向于接受接口,而不是具体类型。
因此返回接口是一个糟糕的做法
为什么?
对比一下两者的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ( "fmt" ) type Reader interface { Read() string } type FileReader struct { filename string } func (f *FileReader) string { return "Reading from file: " + f.filename } func GetReader () return &FileReader{filename: "data.txt" } } func main () reader := GetReader() fmt.Println(reader.Read()) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ( "fmt" ) type Reader interface { Read() string } type FileReader struct { filename string } func (f *FileReader) string { return "Reading from file: " + f.filename } func GetFileReader () return &FileReader{filename: "data.txt" } } func main () reader := GetFileReader() fmt.Println(reader.Read()) fmt.Println("Filename:" , reader.filename) }
当然万事不是绝对的,比如我们经常error返回接口
总结 接口是一种抽象,一般用于
最后以一句名言来结尾:
要尽可能的简单,但保持简单已经开始变得不简单